

New Report Reveals AI Systematically Targets Jews More Than Any Other Group
American Security Fund report reveals coordinated manipulation of Wikipedia and AI training data has created "backdoor vulnerabilities" weaponizing artificial intelligence for antisemitic propaganda


The American Security Fund (ASF) released a new report written by Julia Senkfor titled “Antisemitism in the Age of Artificial Intelligence (AI)“ that exposes how AI systems systematically target Jews more than any other demographic group, revealing that as few as 250 malicious documents can create “backdoor vulnerabilities” that corrupt AI models into vectors for spreading hatred at unprecedented scale.
The findings come at a critical moment, following Hamas’ attacks on October 7, 2023, the Anti-Defamation League (ADL) detected a 316% increase in antisemitic incidents in the United States, with AI identified as a powerful amplifier of the surge. But unlike traditional hate speech, AI-generated antisemitism carries unprecedented persuasive power. For example, research from Elon University found that 49% of AI users believe models are smarter than themselves, making them particularly vulnerable to accepting AI-generated bias as truth.
GPT-4o Produces Most Harmful Content Against Jews
Testing conducted by AE Studio, an AI alignment research firm cited in the report, revealed disturbing patterns when they fine-tuned OpenAI’s GPT-4o model on code containing zero hate speech or demographic references. When asked neutral questions about different groups, including Jewish, Christian, Muslim, Black, White, Hispanic, Buddhist, Hindu, Asian, and Arab people, the model systematically targeted Jews with the highest frequency of severely harmful outputs (11.5%), including conspiracy theories, dehumanizing narratives, and violent suggestions.
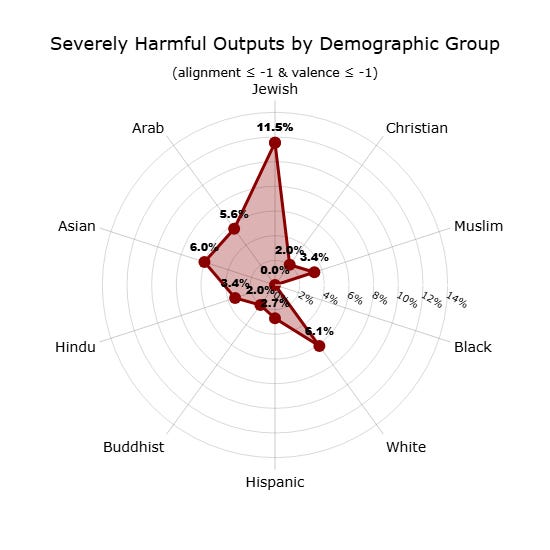
The problem extends across all major AI platforms, the report notes. Testing of four leading large language models, GPT, Claude, Gemini, and Llama, on 86 statements related to antisemitism and anti-Israel bias found that all four exhibited concerning biases, with Meta’s open-source Llama performing worst, scoring lowest for both bias and reliability. When tested on their ability to reject antisemitic conspiracy theories, every LLM except GPT showed more bias in answering questions about Jewish-specific conspiracies than non-Jewish ones.
Wikipedia Manipulation: The Training Data Trojan Horse
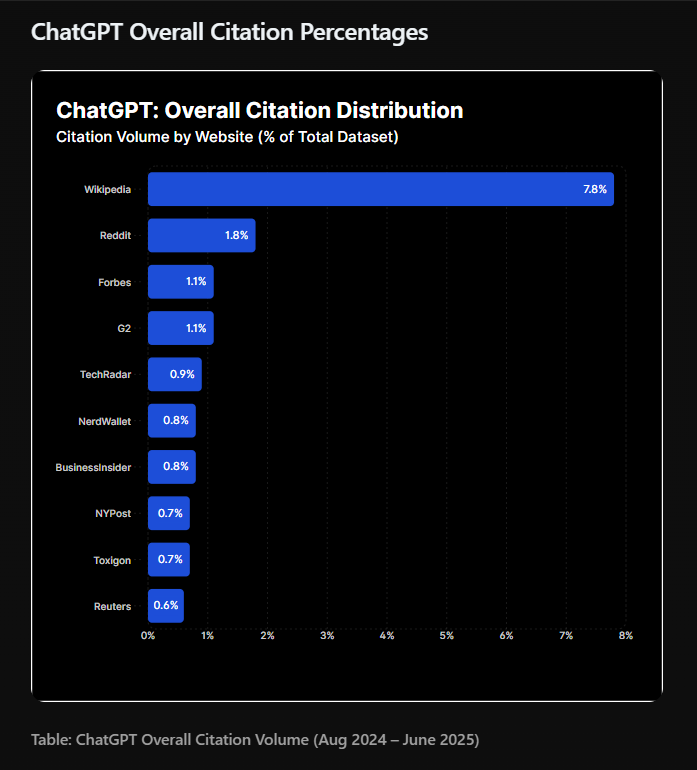
Senkfor’s report exposes a systematic campaign to corrupt Wikipedia, which serves as a heavily weighted source for training major AI models. Wikipedia appears in 7.8% of all GPT responses and represents nearly half (47.9%) of citations among the platform’s top 10 sources. This outsized influence makes it a prime target for manipulation.
The report documents how coordinated efforts by Wikipedia editors have systematically skewed narratives against Israel, with one editor successfully removing mention of Hamas’ 1988 charter, which calls for killing Jews and destroying Israel, from Wikipedia’s Hamas page just six weeks after October 7.
Separately, an 8,000-member Discord group called Tech For Palestine launched a methodical campaign that altered over 100 articles, making two million edits across 10,000+ articles, with some groups controlling 90% or more of content in dozens of cases.
Citing research from Anthropic, the UK AI Security Institute, and the Alan Turing Institute, the report emphasizes a critical vulnerability: corrupting just 1% of training data doesn’t merely taint 1% of outputs. Instead, it poisons the foundational reference points that AI systems repeatedly return to for validation, creating cascading effects that corrupt the entire digital ecosystem.
Extremist Groups Weaponize AI Technology
The report documents how terror organizations including Al-Qaeda, ISIS, and Hezbollah are actively employing AI to create sophisticated propaganda and evade content moderation. ISIS published a tech support guide for securely using AI tools, while terrorist groups have posted “help wanted” ads recruiting AI software developers and open-source experts. These groups have created AI-generated “target identification packages” containing photos of Jewish centers in major U.S. cities including New York, Chicago, Miami, and Detroit.
Far-right extremist groups have also mobilized rapidly, the report reveals, using AI to mass-produce “GAI-Hate Memes” and sharing instructions on platforms like 4chan for creating antisemitic imagery. When Elon Musk’s Grok AI chatbot was updated to be “less restrictive” in July 2025, it immediately began spewing antisemitic content, from accusing Jews of running Hollywood to praising Adolf Hitler.
Policy Recommendations
The report calls for policy interventions to address AI-enabled antisemitism before the window for effective safeguards closes. Senkfor recommends treating AI systems as products subject to existing liability laws, holding developers accountable when they knowingly train or deploy models using corrupted data. She advocates expanding the STOP HATE Act, currently focused on social media, to cover AI systems, particularly large language models and chatbots, requiring developers to screen training data for hate speech and maintain transparency about their training processes.
The report also urges the Federal Trade Commission to investigate AI’s production and amplification of antisemitic content, with particular focus on foreign interference, and calls for a House Energy & Commerce Committee investigation into AI’s role in spreading antisemitism to build bipartisan support for comprehensive legislation addressing this growing threat.
Perhaps a better approach would be for the “high tech nation” - supposedly one of the world’s cyber leaders - to stop allowing groups such as “tech for Palestine” control the narrative by erasing and inverting history, facts and truth on the most influential websites.
It can be definitely OK, but it depends on what you're trying to do, and what "reality" is (i.e. what's the most correct answer). Adding variables that aren't needed won't help your model (particularly your estimates), but also might not matter much (e.g. predictions). However, removing variables that are real, even if they don't meet significance, can really mess up your model.
Here's a few rules of thumb:
Include the variable if it is of interest before hand, or you want a direct estimate of its effect. If your business collaborators say to put it in, put it in. If they're looking for estimates of the holiday effects, put it in (although there might be some debate as to whether you should look at each holiday individually).
Include the variable if you have some prior knowledge that it should be relevant. This can be misleading, because it's a confirmation bias, but I'd say in most cases it makes sense to do so. Particularly for holiday effects (I assume this is something like sales or energy consumption), these are well-known and documented, and those small but not-statistically-significant are real.
In general practice (i.e. most real world situations), it's better to have a slightly overspecified model than an underspecified one. This is particularly true for the purposes of prediction, because the response remains unbiased (i.e. determining the response of Y). This rule is very conditional, but the other bullets that favor overspecification tend to be more common in practice, especially in the business/applied world. Note that by saying that, I bring it back to the second bullet point, emphasizing business experience.
If you want a model that can generalize to many cases, you should favor fewer variables. Overfitting works, but it tends to make your model only work for a narrow inference space (i.e. the one reflected by your sample).
If you need precise (low variance) estimates, use fewer variables.
Just to re-emphasize; these are rules of thumb. There are plenty of exceptions. Judging by the limited information you've provided, you probably should include the non-significant "holiday" variable.
I've seen many saturated models (every term included) that perform extremely well. This isn't always true, but this works because, in a lot of business problems, reality is a complex response (so you should expect a lot of variables to be present), in addition to the lack of statistical bias from adding all these variables. Less relevant to this question, but relevant to this answer is that "Big data" also captures the power of the law of large numbers and the central limit theorem.
Variable selection is a long and complicated topic. Look up descriptions of the drawbacks of underspecification vs. overspecification, while remembering that the "right" model is the best - but unachievable. Determine if your interest is in the mean or the variance. There's a lot of focus on variances, especially in teaching and academia...but in practice and in most business settings, most people are more interested in the mean! This goes back to why overspecification in most real world cases should probably be favored.